
Maestro: The Infinite AI Sample Generator
Generate royalty-free loops, one-shots, and FX from text. Try for free—unlimited plans available.
Today we launched Maestro: our state-of-the-art model that generates studio-quality audio samples from text descriptions. It was trained on synthetic and ethically sourced data and designed for how producers and audio engineers actually work.
You can try Maestro for free in your browser — no credit card needed. Paid plans unlock unlimited generations, unlimited downloads, and the desktop application for macOS and Windows.
Check out audio examples on the product page.
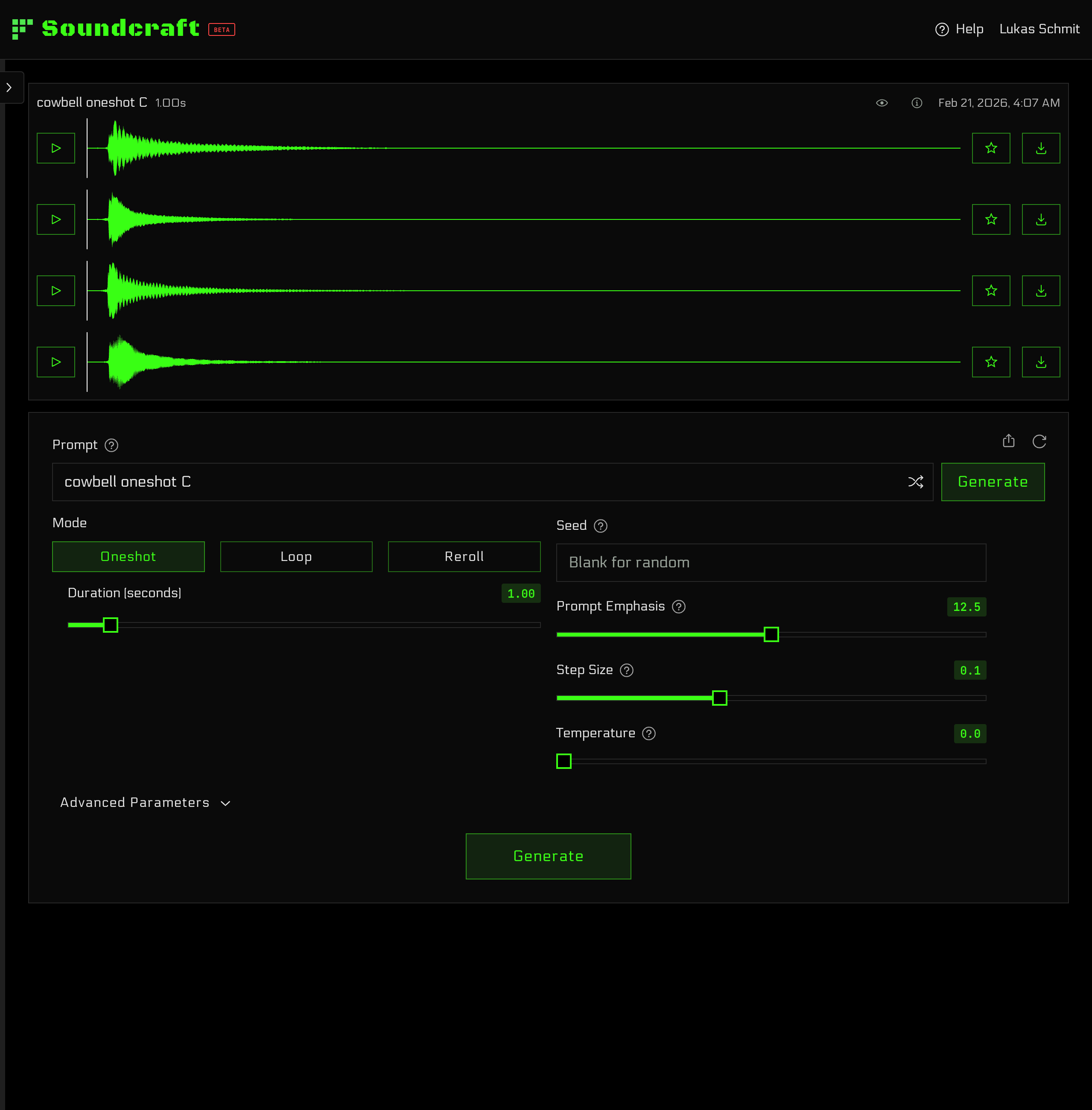
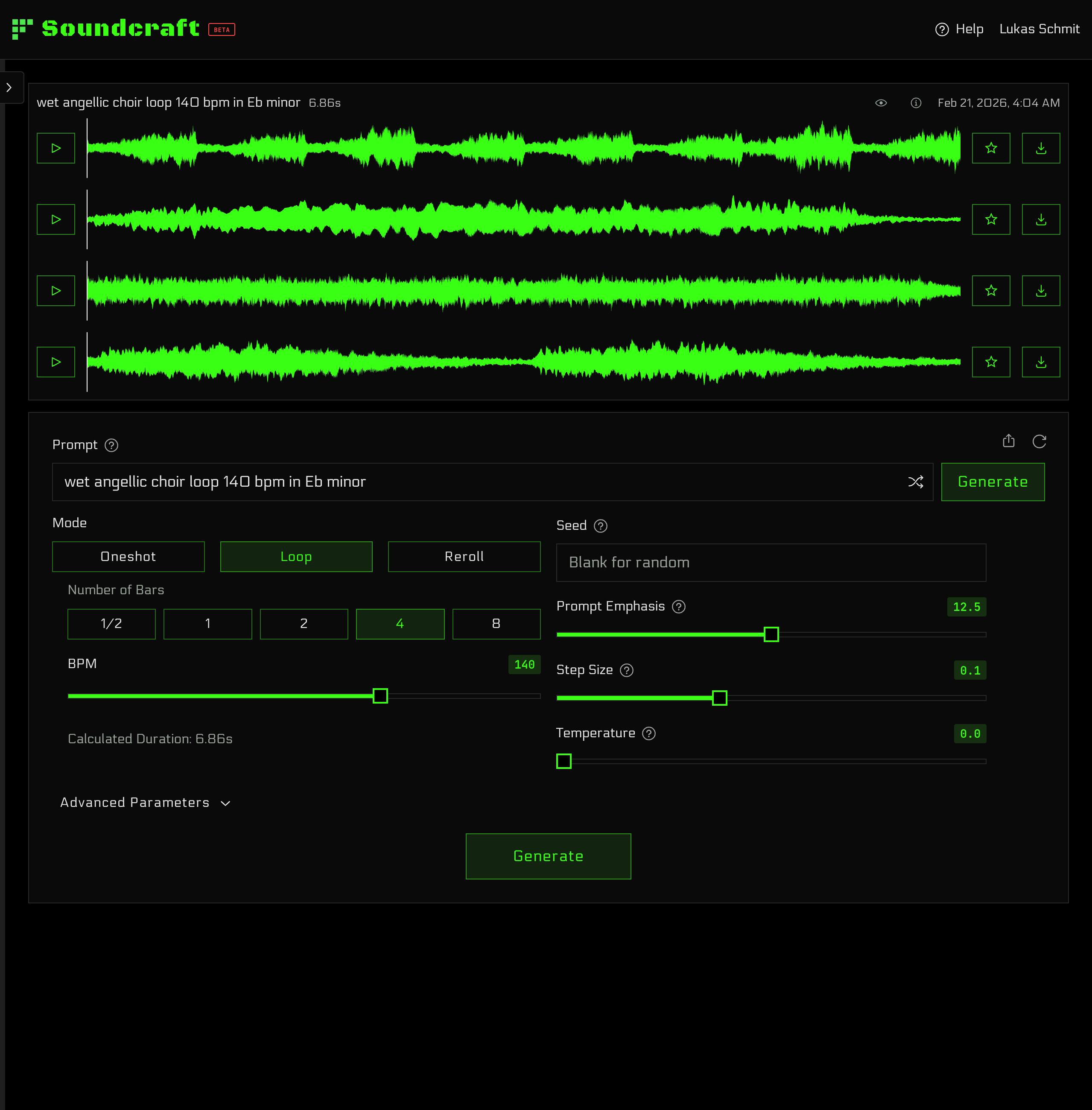
Built for Producers
Maestro does not produce finished tracks. That's your job. Our model was designed to make samples: one-shots, loops, FX, and more. Use it to create the specific sound you need to finish your project, or explore unheard sounds for endless inspiration.
Samples should fit your projects—not the other way around. Maestro gives you precise control over duration, BPM, key, and more. Create samples ready to drop into any project or DAW.
Maestro can generate endless variations from any prompt. This means every sample you create is completely unique. Never worry about someone else recognizing your samples.
Our model architecture even allows you to "reroll" or "flip" samples into new sounds. Subtle tweaks or drastic reimaginings are a click away. It's a new kind of synthesis you have to try to believe.
And most importantly, fidelity is paramount. Every sample is rendered in stereo at 48 kHz and is available for download as a lossless .wav.
The Model
Why Not Autoregressive?
Maestro is not autoregressive: it does not generate audio from left to right, one token at a time. Although autoregressive LLMs have been shown to scale reliably on many tasks, they have several key limitations for our use case:
- Speed: Autoregressive models are slow and expensive. Fast iteration is a must for creative workflows.
- Duration: It is hard to control the duration of the output—autoregressive models decide when to stop.
- Flexibility: Features like "rerolling" and "inpainting" are difficult with an autoregressive architecture.
Equilibrium Matching
Maestro is trained with Equilibrium Matching, a novel generative framework. Similar to diffusion models, it iteratively denoises a sample to produce target audio. Critically, since we start with a random noise sample, we can control the exact duration of the output audio. Generating all time steps in parallel is fast: Maestro can generate four different ten-second samples in under a second.
Since there are effectively infinite random starting points, Maestro can generate endless variations from the same prompt. This is also what makes "rerolling" possible: by partially corrupting a sample with a controlled amount of noise (the temperature parameter), Maestro can produce anything from subtle variations to drastic reimaginings.
The Architecture
Under the hood is our state-of-the-art foundation model: a multi-billion-parameter transformer with dual-stream joint attention over text and audio representations. A large pretrained text encoder processes prompts for rich semantic understanding, while the audio stream operates on the compact latent space of a high-fidelity autoencoder. We adopted several modern techniques, including multimodal RoPE, LayerNorm scaling, classifier-free guidance, and a preconditioned optimizer. Maestro was trained for over a month on B200 GPUs.
The Data
Great models need high-quality data and lots of it. Maestro had very specific needs:
- Samples, Not Songs: Maestro generates one-shots and loops, not finished tracks.
- Accurate Descriptions: For training, we needed detailed text descriptions of every sample. Not just tags and genres, but detailed descriptions of timbre, rhythm, and melody.
- Studio Quality: High-fidelity, stereo audio was a must. Garbage in, garbage out.
- Ethical and Legal: Large-scale web scraping is a common practice at many frontier labs, but we don't believe in stealing artists' work.
There are several open datasets, but none of them met these criteria. Specifically, rich text descriptions are hard to come by. We tried to bootstrap text labels (e.g., using an LLM to generate descriptions), but even the best models still struggle to understand audio well.
Ultimately, we realized we'd have to create the dataset ourselves. We started by building our own wavetable synthesizer (more on that soon), designed with LLMs in mind—exposing every parameter through a text interface.
We built an agentic sound design system based on an actor-critic architecture. The actor agent takes a description of a sound and iterates on the synth patch to produce it, while the critic listens to the output and judges whether the output matches the description. We used this system to generate tens of thousands of presets—each with a precise text description of the timbre.
Finally, we used our synth and presets to generate synthetic audio-text pairs. By varying MIDI patterns, keys, BPM, etc., we were able to cover diverse styles with accurate labels. This pipeline is entirely algorithmic, allowing us to generate tens of millions of samples without GPUs. To increase model's breadth, we also incorporated various open data sources, including sound effects, acoustic instruments, and more.
Maestro's training was conducted in two stages: pretraining on diverse genres of copyright-free music to give Maestro a broad musical prior, then finetuning on synthetic text/sample pairs plus open effects data.
What's Next
Maestro is our first product, and we can't wait to see what you'll make with it. Expect frequent updates with improvements in quality, diversity, and controllability. We welcome all feedback, both positive and negative.
Stay tuned, and happy crafting.
The Soundcraft Team